

How To Create Training Data Set In Matlab
How to Build A Data Fix For Your Machine Learning Project

Are you well-nigh thinking AI for your organization? You have identified a use case with a proven ROI? Perfect! but not then fast… practice you lot have a data set?
Well, well-nigh companies are struggling to build an AI-set data set or perhaps simply ignore this event, I thought that this article might help you a little bit.
Let'southward beginning with the basics…
A information gear up is a collection of data. In other words, a data set corresponds to the contents of a single database tabular array, or a single statistical information matrix, where every column of the table represents a detail variable, and each row corresponds to a given member of the data gear up in question.
In Machine Learning projects, we need a grooming data ready. It is the bodily data gear up used to train the model for performing various actions.
Why do I demand a data set?
ML depends heavily on data, without information, information technology is impossible for an "AI" to learn. It is the most crucial aspect that makes algorithm training possible… No matter how swell your AI team is or the size of your data gear up, if your information set is not good enough, your entire AI project will neglect! I have seen fantastic projects fail because we didn't take a good information set despite having the perfect apply example and very skilled data scientists.
A supervised AI is trained on a corpus of preparation data.
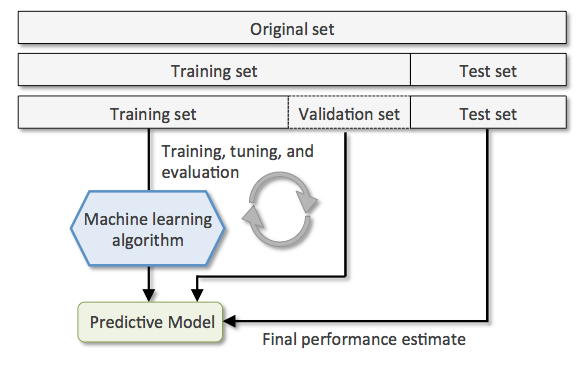
During an AI development, nosotros ever rely on information. From training, tuning, model selection to testing, we utilise three different data sets: the training set, the validation ready ,and the testing set up. For your data, validation sets are used to select and melody the concluding ML model.
Y'all might remember that the gathering of information is enough merely it is the opposite. In every AI projects, classifying and labeling information sets takes near of our time , especially data sets accurate plenty to reflect a realistic vision of the market/world.
I want to innovate you to the get-go 2 data sets nosotros need — the training data set and test information set because they are used for different purposes during your AI project and the success of a project depends a lot on them.
- The training data fix is the 1 used to train an algorithm to understand how to apply concepts such equally neural networks, to learn and produce results. It includes both input data and the expected output.
Grooming sets make up the majority of the full data, around 60 %. In testing, the models are fit to parameters in a procedure that is known as adjusting weights.
- The test data set is used to evaluate how well your algorithm was trained with the grooming data prepare. In AI projects, we can't employ the preparation data set in the testing stage because the algorithm will already know in advance the expected output which is not our goal.
Testing sets stand for 20% of the data. The test fix is ensured to exist the input data grouped together with verified correct outputs, by and large by human verification.
Based on my feel, it is a bad idea to attempt further adjustment by the testing stage. Information technology will probable pb to overfitting.
What is overfitting?
A well-known issue for data scientists… Overfitting is a modeling error which occurs when a office is also closely fit to a express set of information points.
How much information is needed?
All projects are somehow unique simply I'd say that you need x times as much information every bit the number of parameters in the model being built. The more complicated the task, the more data needed.
What type information practise I demand?
I always start AI projects past asking precise questions to the company conclusion-maker. What are you trying to accomplish through AI? Based on your answer, you need to consider what data you really need to accost the question or problem y'all are working on. Make some assumptions about the data you require and be conscientious to record those assumptions so that y'all can test them later if needed.
Below are some questions to assist you :
- What data tin can you use for this project? You must have a clear picture of everything that you can use.
- What data not bachelor you wish you had? I like this question since we can ever somehow simulate this information.
I have a data set, what now?
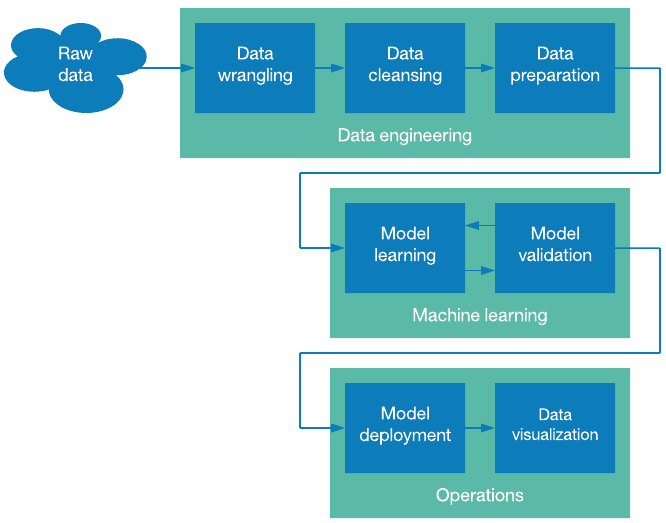
Not so fast! You should know that all information sets are innacurate. At this moment of the projection, we need to do some data preparation, a very important footstep in the auto learning process. Basically, information training is about making your data set more suitable for automobile learning. It is a set of procedures that consume most of the time spent on automobile learning projects.
Even if y'all have the data, you can still run into problems with its quality, as well as biases hidden inside your grooming sets. To put information technology simply, the quality of training data determines the operation of auto learning systems.
Have you lot heard nearly AI biases?
An AI can be easily influenced… Over the years, data scientists accept found out that some popular information sets used to train epitome recognition included gender biases.
As a issue, AI applications are taking longer to build because we are trying to brand sure that the information is correct and integrated properly.
What if I don't have plenty data?
It tin happen that you lack the data required to integrate an AI solution. I am not gonna lie to y'all, it takes time to build an AI-ready information set if y'all notwithstanding rely on newspaper documents or .csv files. I would recommend yous to first take time to build a modern information collection strategy.
If you already adamant the objective of your ML solution, you tin can enquire your team to spend time creating the information or outsource the process. In my latest project, the visitor wanted to build an image recognition model but had no pictures. As a consequence, nosotros spent weeks taking pictures to build the data fix and finding out ways for hereafter customers to do it for us.
Do you have a data strategy?
Creating a data-driven culture in an arrangement is maybe the hardest part of existence an AI specialist. When I endeavor to explain why the visitor needs a data culture, I can come across frustration in the eyes of most employees. Indeed, data collection can exist an annoying task that burdens your employees. However, we can automate most of the information gathering process!
Another issue could be data accessibility and buying… In many of my projects, I noticed that my clients had enough data, but that the information was locked abroad and hard to access. You must create connections betwixt data silos in your organization. In club to become special insights, you must gather data from multiple sources.
Regarding ownership, compliance is also an result with data sources — just considering a company has access to information, doesn't mean that information technology has the right to use it! Don't hesitate to enquire your legal squad nigh this (GDPR in Europe is one case).
Quality, Scope and Quantity !
Machine Learning is not only nigh large information prepare. Indeed, you don't feed the organisation with every known information point in whatever related field. We want to feed the system with advisedly curated data, hoping it can learn, and maybe extend, at the margins, knowledge that people already have.
Most companies believe that information technology is enough to gather every possible data, combine them and permit the AI find insights.
When edifice a data set, you should aim for a diversity of data. I e'er recommend companies to gather both internal and external information. The goal is to build a unique data set that will be hard for your competitors to re-create. Machine learning applications do crave a large number of data points, but this doesn't mean the model has to consider a wide range of features.
We desire meaningful data related to the project. You may possess rich, detailed data on a topic that only isn't very useful. An AI expert will enquire yous precise questions about which fields really thing, and how those fields will likely matter to your awarding of the insights you lot get.
In my latest mission, I had to help a company build an image recognition model for Marketing purposes. The idea was to build and confirm a proof of concept. This company had no data set except some 3D renders of their products. We wanted the AI to recognize the product, read the packaging, decide if it was the right production for the customer and help them empathise how to use it.
Our data set was composed of 15 products and for each, nosotros managed to have 200 pictures.This number is justified by the fact that it was nevertheless a prototype, otherwise, I would have needed way more than pictures! This assumes you are making apply of transfer learning techniques.
When information technology comes to pictures, nosotros needed unlike backgrounds, lighting conditions, angles, etc.
Everyday, I used to select 20 pictures randomly from the training set and analyze them. Information technology would give me a good idea of how diverse and accurate the information set was.
Every time I've washed this, I accept discovered something important regarding our data. It could be an unbalanced number of pictures with the same angle, wrong labels, etc.
A adept thought would be to start with a model that has been pre-trained on a large existing data set and utilise transfer learning to finetune information technology with your smaller set of data you've gathered.
Data Preprocessing
Alright, let's back to our information prepare. At this step, you have gathered your data that you estimate essential, diverse and representive for your AI project. Preprocessing includes selection of the right data from the complete information set and building a training set. The process of putting together the data in this optimal format is known every bit feature transformation.
- Format: The data might be spread in different files. For example, sales results from different countries with different currency, languages, etc. which needs to exist gathered together to form a information set.
- Data Cleaning: In this step, our goal is to deal with missing values and remove unwanted characters from the information.
- Feature Extraction: In this step, nosotros focus on assay and optimisation of the number of features. Usually, a fellow member of the team has to find out which features are of import for prediction and select them for faster computations and low memory consumption.
The perfect data strategy
The most sucessful AI projects are those that integrate a data collection strategy during the service/production life-cyle. Indeed, information collection can't exist a series of one-off exercises. It must be built into the core product itself. Basically, every time a user engages with your production/service, you want to collect information from the interaction. The goal is to utilise this constant new information menses to improve your product/service.
When you achieve this level of data usage, every new customer yous add makes the data set bigger and thus the product meliorate, which attracts more customers, which makes the information fix better, and then on. It is some kind of positive circle.
The all-time and long term oriented ML projects are those that leverage dynamic, constantly updated information sets. The reward of building such data collection strategy is that it becomes very hard for your competitors to replicate your data fix. With data, the AI becomes ameliorate and in some cases like collaborative filtering, it is very valuable. Collaborative filtering makes suggestions based on the similarity between users, information technology will improve with access to more data; the more user data one has, the more than probable it is that the algorithm tin find a similar a user.
This ways that you need a strategy for continuous comeback of your data set for as long as at that place's any user benefit to better model accurateness. If yous can, find artistic means to harness even weak signals to admission larger data sets.
One time again, let me use the example of an epitome recognition model. In my final experience, we imagined and designed a way for users to accept pictures of our products and send information technology to us. These pictures would then be used to feed our AI arrangement and brand our system smarter with time.
Another arroyo is to increment the efficiency of your labeling pipeline, for case, we used to rely a lot on a arrangement that could suggest labels predicted by the initial version of the model so that labelers tin brand faster decisions.
Finally, I have seen companies simply hiring more people to label new training inputs… It takes time and money simply it works, though it tin be difficult in organizations that don't traditionally accept a line item in their budget for this kind of expenditure.
Despite what almost SaaS companies are saying, Machine Learning requires time and training. Whenever your hear the term AI, you must remember about the data backside it. I hope that this article will aid you understand the primal role of data in ML projects and convince y'all to take time to reflect on your data strategy.

How To Create Training Data Set In Matlab,
Source: https://towardsdatascience.com/how-to-build-a-data-set-for-your-machine-learning-project-5b3b871881ac
Posted by: campbelldinexpose.blogspot.com
0 Response to "How To Create Training Data Set In Matlab"
Post a Comment